

Kristi Webb is a Senior Consultant at ThreeWill. She has over 18 years of software development experience working on software solutions and integrations for enterprise and product solutions. Her passion is applying technology solutions to solve business problems and improve efficiency.
Introduction
In a previous blog post, we discussed the overall steps for migrating from an older, custom Unily instance to a more current version of Unily, which includes extracting the data from the older version of the product, transforming that data, and then uploading the data into the newer Unily platform. We also covered several of the challenges we have overcome when migrating Unily content.

In this blog post, we will discuss the Unily Data Extraction process in more detail, as well as some of the specific challenges we have overcome when pulling or extracting the data via the Unily APIs.
Inventory Creation

Our first goal is always to get a complete inventory of data in the source system. The inventory includes the following 3 types of data:
- Users
- Sites
- Content (Content Items and Media Files)
For this specific project, we did not migrate Pages and Widgets, but those ‘content types’ are also available via the Content API if you do want to migrate them.
User Inventory
![]()
Using the /users/query API endpoint we created a utility that pulls the list of Unily Users and saves the list of Users into a MongoDB database. We use a paging token to make repeated API calls until the complete list of users is pulled and stored in the database.
Sites & Content Inventory
![]()
We initially pulled just the list of sites using the /content/query API endpoint by filtering only for sites. Later we merged the process of pulling content items and site information into a one-step process and pulled all the content items with their Site ID, Content Store ID, and Repository ID stored together as one document record in a MongoDB database. Once in the database, we can run various queries and analyze the content to help determine which items should be migrated. We can also see how many content items exist within a site to allow us to group sites into realistic batches that can be migrated daily. We are also able to assess which sites have new or recently modified content.
Content Details Stored in Document Database
Here is a listing of the fields we store on each Content Item document in the MongoDB document database:
- Content Item ID
- Content Item Unique ID (GUID)
- Content Item Name
- Created Date
- Last Modified Date
- Content-Type (“nodeTypeAlias” in Unily)
- Content Item Parent Node ID
- Site ID
- Site Unique ID (GUID)
- Site Name
- Content Store ID
- Content Store Unique ID (GUID)
- Content Store Name
- Repository ID
- Repository Unique ID (GUID)
- Repository Name
- Repository Type
- Source Content JSON
- Transformed Content JSON (blank until transform action is completed. this will be uploaded to the target system)
Storing all these details with the content JSON makes the transformation and upload processes more efficient and easier to manage.
Pulling Media Files

In addition to the Unily Content Items, the related binary files are stored in a separate ‘Media’ location. For this project, Unily created a custom API endpoint for our customer that provided a complete Media Inventory list. This allowed us to create a Media items inventory earlier in the project during the planning stage. Over time, our tool and extraction process has evolved to be more efficient where we now pull the Media item and its related binary file real-time during the production migration, whenever a content item referenced or included a media file. The entire pull of the content item plus a related media file involves at least 3 separate API calls:
- Pull the Content Item
- Pull each related Media Items (the Media item is a JSON object that contains all relevant metadata about the binary file)
- Pull each Media Item’s actual binary file
Unily Data Extraction
The following section walks through some additional challenges we have overcome when working with the Unily platform to extract data.
Site, Content Store, Repository Hierarchy

Each site has one or more content stores, which then contain one or more repositories. The repositories are containers that usually house content items that all have the same content type but there are some exceptions to this rule, and those will be explained below in more detail. Pulling the actual content items requires us to traverse this Unily specific information architecture recursively to ensure all content is captured.
Published vs Unpublished Content
The Content API returns both published and unpublished content. Depending on your migration needs, the unpublished content can be ignored or extracted for future migration. Of course, when a content store or repository is unpublished, we have found cases where they contain both published and unpublished content items. We learned that Unily treats everything under an unpublished content store or repository as ‘unpublished’ content regardless of the individual content item’s status.
Trashed Content

Unily has the concept of ‘trashed’ content that was deleted by an end-user, so we exclude this content from our API requests. Of course, this approach could be changed if trashed content should be kept for archive purposes.
Topics
Topics are like categories that are used to identify similar content items. The topics are stored under the ‘Managed Metadata’ section in the Content Management Store and each topic has a unique ID. We pull the list of topics and their IDs so we can create the equivalent topics in the target Unily system and keep track of the equivalent topic ID mappings.
Subsites
For the migration, the sites and their related subsites were being manually provisioned in the new target system. Each site ID was mapped to the equivalent in the target Unily system, so we did not need to track the hierarchy relationship between sites and their related subsites, although this information is available in the MongoDB database if the hierarchy needs to be built programmatically.
Additional Exceptions
The following are unexpected exceptions that occurred when extracting the data and producing the inventory of all the sites and content. The inventory code in our utility handles all these exceptions:
- Insight Repositories
Insight repositories often contain folders that designated which author’s content is in each folder. We capture this additional level of content by inventorying the folders and extracting any Insight content in each folder. - Multiple Content Stores are Possible
A few sites may have more than one content store, although this is rare. The content pull checks for additional content stores so no items are missed.
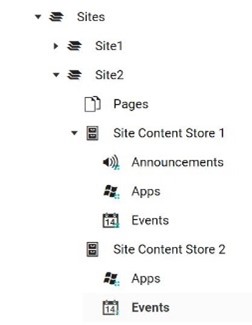
- Multiple Repositories of the same type are Possible
The same type of repository can exist more than one time in a site content store. Often this is done to segment the same type of content into smaller groupings for presentation in the widgets. The inventory pulls all this content while also keeping track of each content item’s parent repository in case the same groupings should be persisted during migration. - Repositories that contain Other Repositories
Some repositories may be configured to house other repositories and not just content items. Obviously, these repositories within a repository must be further searched for additional content items. This may not exist in your Unily instance, but our inventory code handles this scenario as well. - Repositories that contain Multiple Types of Content
A custom repository may be configured to allow more than one type of content to be stored within the one repository. Again, the inventory code handles this situation, but it may not apply to your Unily instance.
What’s Next
This blog post covered the key points and learnings when extracting data out of Unily. In the next blog post, we will dive into the Transform details and explain several types of data transformations we apply as we modify the content JSON or media JSON before uploading to the new destination. Many transformations are standard in all our migration projects, but there are some Unily specific details that must be addressed to ensure the content and media items are successfully pushed into the new target system.
Next, we explore how to upload Unily content successfully during a migration. Unily Migration Step 2: Data Transformation
CONTACT THREEWILL TO LEARN MORE ABOUT UNILY MIGRATIONS TODAY!