

Kristi Webb is a Senior Consultant at ThreeWill. She has over 18 years of software development experience working on software solutions and integrations for enterprise and product solutions. Her passion is applying technology solutions to solve business problems and improve efficiency.
Overview of Unily Migrations Introduction
The ThreeWill Transformation team recently worked on a project upgrading from an earlier, customized version of Unily to the latest Unily platform. We were asked by Unily to assist with the migration of the content using their recently released public APIs. Due to all the customizations in the older Unily instance, Unily asked ThreeWill to help migrate the data.
We have worked with Unily on previous migrations into their platform, and we were happy to bring our migration best practices and experience to this project as well.
The Approach
Regardless of the type of source and destination systems for a migration project, we employ the same 3-step ETL (Extract, Transform and Upload) process for any migration:
- EXTRACT: First we EXTRACT the content and necessary metadata/configuration data from the source system. Of course, in this case, it was Unily.
- TRANSFORM: Second, we TRANSFORM that content in whatever way is necessary to prepare for migration.
- UPLOAD: Third, we ensure successful UPLOAD of the content into the correct locations in the destination system. In this case, it was a more recent version of Unily.
Transform is the most complex step with challenges such as updating embedded references and links to data in the source system that will now reside in a new destination system, and that mapping must be applied carefully so the migrated content will work correctly after migration. In this migration project, even users had to be mapped to their new User IDs in the destination system since Unily has a different User ID for the same person in both versions of their application.
This blog post is the first post in a four-part blog series. The additional blog posts will each cover the extract, transform, and upload details for this ‘Unily to Unily’ migration.
Specific Challenges Encountered
Unily APIs are New

One of the big picture challenges that we ran into was the fact that the Unily APIs are very new and we were using the first generation (v 1.0). Of course, the Unily API technical team was excellent to work with and very responsive to our requests for information and updates, but the API documentation was limited especially for implementing the queries to extract out targeted data.
Multiple Options for Extracting Content
Specifically related to the Unily APIs, we also had to learn the difference between the Content and Search APIs to understand if we were seeing both the published and unpublished content, or just the published content, respectively. This subtle difference could be important if you want to persist the unpublished content as well.
Unily Field Name Inconsistencies
Some of the Unily APIs allowed for GraphQL search queries which were very powerful; however, determining the exact field names was challenging in some cases since the Unily CMS administrative tools for developers would display some field names that did not work in APIs. You just had to know what field name was expected by the APIs in a few cases.
Unily API Scopes and Settings
We also had to work with the Unily technical resources to get the correct set of ‘API Scopes’ applied to our API credentials so we could be authorized to use all the API endpoints that were needed for the full migration. Determining which scopes you needed were an additional learning curve. We also worked with Unily to increase the number of API calls per minute in both the source and destination instances of Unily. By default, this threshold is limited to 20 API calls per minute but working with Unily this was increased to 90 API calls per minute to avoid errors during the actual migration.
Media Binary Files
Migrating the binary files, which Unily refers to as ‘Media’ files, was also challenging. We had to determine how to get the related media binary documents via the API and bring those over to the new destination location while maintaining the correct relationships between the media files and the content items that reference them. It requires 3 separate API calls to pull all the required information when a content item references a media item.

Unily Information Architecture Complexities
Understanding the Unily data information architecture (IA) was also critical to ensure the correct data would be extracted. For example, the content API endpoints return a wide range of ‘content’ since story items, pages, widgets on the pages, repositories for the story items, and even the sites where all these items are found are all considered content items. Most systems we have worked with separate the containers from the user consumable content with separate API calls, but Unily stores all these together as content items. Of course, this can be efficient if you want everything at one time, but we needed to migrate the user consumable content by site, so a group of known sites could be migrated together in a batch at a specific time. We had to learn how to properly query the content to keep track of these site container relationships and more efficiently pull only the content items we wanted to extract.
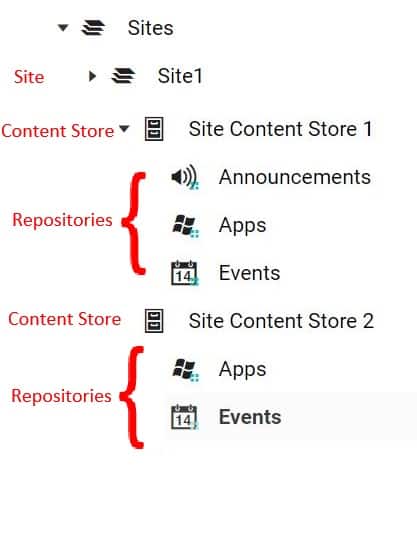 Even within a site, there are further container levels. Each Site in Unily will have 1 or more content stores, which in turn will have 1 or more Repositories where the actual content items are stored. You must understand this hierarchy for each site and know how to traverse the Content APIs to get to the actual content items that will be migrated, while also keeping track of the IA structure if you are replicating the same structure in the destination system.
Even within a site, there are further container levels. Each Site in Unily will have 1 or more content stores, which in turn will have 1 or more Repositories where the actual content items are stored. You must understand this hierarchy for each site and know how to traverse the Content APIs to get to the actual content items that will be migrated, while also keeping track of the IA structure if you are replicating the same structure in the destination system.
What’s Next
In the next blog post, we will dive into the Extract details and explain how to address some of the challenges described above when working on a Unily migration. We will also explain how to pull a full inventory of the Sites, Contents, and Media files so someone can plan out the production migration and organize the migration into batches. The full inventory can be used to establish a known migration schedule that allows site owners and users to plan for minimal impact in their day-to-day business operations. This full inventory can also be used for content rationalization to narrow down which content will be migrated when the opportunity to remove older content is a viable option. The next blog post will also cover how individual media files are extracted from the source Unily system since this requires multiple Unily API calls in a specific order.
Next: Unily Migration Step 1: Data Extraction
CONTACT THREEWILL TO LEARN MORE ABOUT UNILY MIGRATIONS TODAY!
1 Comment
Kirk Liemohn
Great start to this blog post series! I had forgotten how complex it was to extract the data until you reminded me. I look forward to reading the other posts in this series.